

GPU server- 从0开始的部署流程
以下是以Ubuntu22.04标准镜像为例,且默认使用root用户,如果你不是root用户请在每条命令前加上sudo
换源&更新软件源&更新内核(可选)
一般选择清华源或者阿里源,或者所在云厂商的源(如果你使用的云服务器,一般不需要换源)
我喜欢清华源
由于内容具有时效性,请前往ubuntu | 镜像站使用帮助 | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror查看
vim /etc/apt/sources.list替换成以下
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-updates main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-backports main restricted universe multiverse
deb http://security.ubuntu.com/ubuntu/ jammy-security main restricted universe multiverse以上完成换源操作
然后是更新软件源
apt update!!!非必要情况不要执行软件升级或者内核升级,会带来很多麻烦
但是笔者喜欢解决麻烦,所以直接执行了
apt upgrade 安装N卡驱动&fabricmanager&CUDA(可选)
作为一台带GPU的服务器,最大的区别是啥呢?
是机器上的GPU!通常情况下GPU服务器默认是指带NVIDIA GPU的服务器,笔者有幸也玩过几天昇腾系列的GPU服务器,但是本文将会以NVIDIA系列为主。
添加NVIDIA软件源
一台ubuntu服务器安装NVIDIA相关的包,其实最佳的操作是通过软件源进行安装,可惜截止2024年,网上的大部分教程还是复古地从run包或者离线包进行安装,实在可惜。
软件源的方式核心就是Index of /compute/cuda/repos (nvidia.com)
国内镜像为Index of /compute/cuda/repos (nvidia.cn),拥有不错的速度
在GPU服务器能连上公网时可以通过这俩个源进行nvidia相关软件的安装,无法访问公网时可以在内网环境自建同步这个源的镜像站来达成(很多云厂商其实已经同步了)。
首先是添加这个源,以下俩中方式二选一
安装密钥方式(不推荐)
wget https://developer.download.nvidia.cn/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb
#注意ubuntu的版本号
#20或者18版本的ubuntu支持的cuda版本更少,但不代表不能用,所以使用2204
dpkg -i cuda-keyring_1.0-1_all.deb
apt clean all && apt update此种方式你需要需要到/etc/apt/sources.list.d下面,把cuda-ubuntu2204-x86_64.list文件里面的网址中的.com也换成.cn才能使用国内镜像加速
添加软件源方式(推荐)
apt-key adv --fetch-keys https://developer.download.nvidia.cn/compute/cuda/repos/ubuntu2204/x86_64/3bf863cc.pub
#注意ubuntu的版本号
#20或者18版本的ubuntu支持的cuda版本更少,但不代表不能用,所以使用2204
vim /etc/apt/sources.list.d/nvidia.list添加以下内容并保存
deb https://developer.download.nvidia.cn/compute/cuda/repos/ubuntu2204/x86_64 /
#注意ubuntu的版本号
#20或者18版本的ubuntu支持的cuda版本更少,但不代表不能用,所以使用2204执行
apt clean all && apt update禁用自带源(可选)
主要是ubuntu的jammy-proposed/restricted 的nvidia驱动源,这个源过于激进,偶尔会放出超前的版本
比如笔者此时可以通过这个源安装nvidia-driver-550 | 550.67-0ubuntu1.22.04.1版本的驱动,会产生各种复杂后果
vim /etc/apt/sources.list将deb http://XXXXXXX/ubuntu/ jammy-proposed main restricted universe multiverse所在行改为
deb http://XXXXXXX/ubuntu/ jammy-proposed main universe multivers
然后执行
apt clean all && apt update即可最小影响禁用
安装N卡驱动&fabricmanager
首先笔者要说明一下,为什么笔者推荐将俩者一起安装。
N卡自安倍系列以来,出现了NVLINK并禁止了通过PCIE进行GPU to GPU的通信。
如果你使用的显卡是除3090外的消费级显卡(包括4090在内)是没有NVLINK的,可以不用安装fabricmanager。
如果你使用的显卡是安倍系列以前的专业算力卡,或者是不使用NVLINK的专业卡,可以不用安装fabricmanager。
此外你都需要fabricmanager才能使用CUDA!!!
但是fabricmanager需要与驱动同一版本,所以笔者强烈推荐不管是否需要fabricmanager,可以在安装驱动的同时和fabricmanager一并安装,因为有时驱动的更新速度是快于fabricmanager的。
查看能装哪些版本
apt-cache search cuda-drivers-fabricmanager笔者此处选择安装当时最新版本的驱动&fabricmanager
apt install cuda-drivers-fabricmanager-550安装好后,你可以使用以下命令查看你的nvidia驱动版本,以及支持的最大cuda版本(不绝对)
nvidia-smi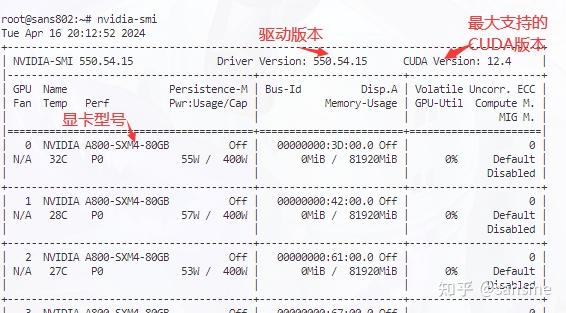
加载fabricmanager
注意,如果你不需要用NVLINK则不需要执行这一步
systemctl enable nvidia-fabricmanager.service --now可通过以下命令查看状态,通常情况下为active
systemctl status nvidia-fabricmanager.service
此时你可以通过NVIDIA的命令显示你的显卡拓扑图
nvidia-smi topo -m这里依旧是以笔者的机器为例
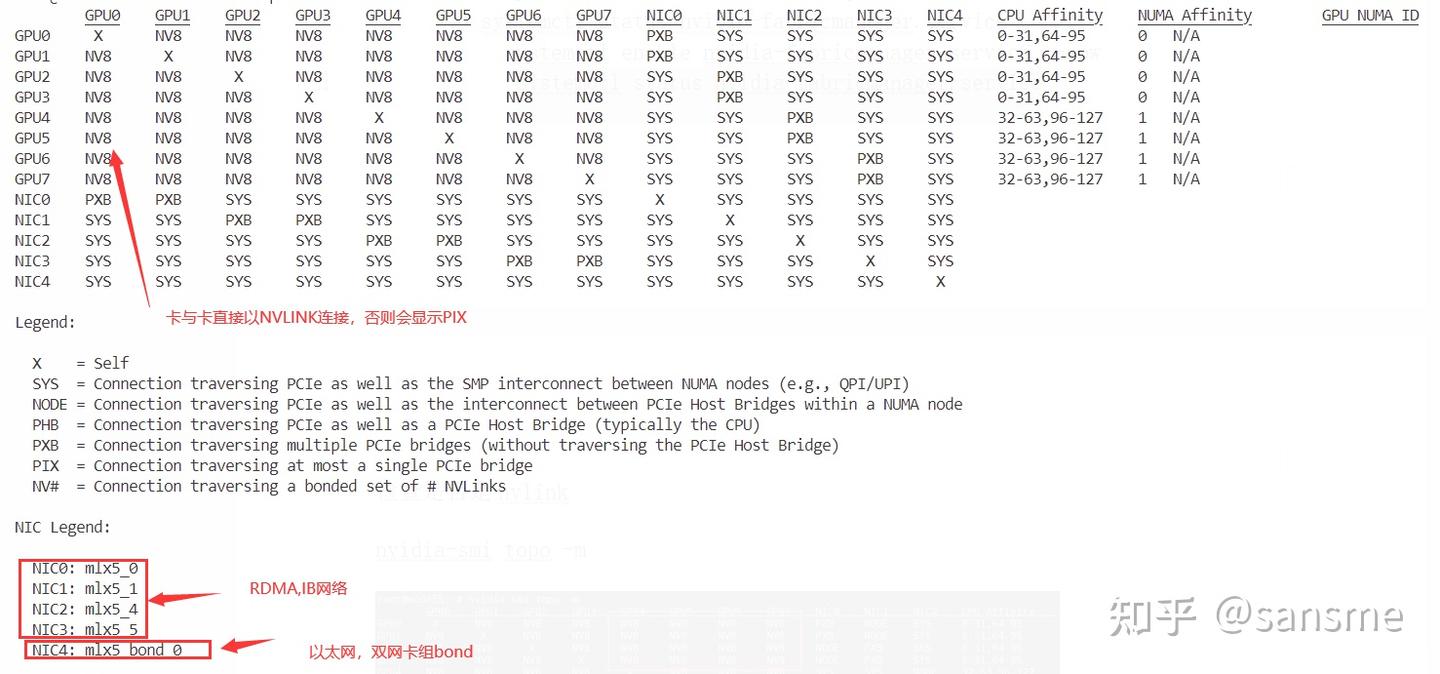
可以看出笔者手里的机器是拥有NVLINK和IB网络的GPU服务器
安装CUDA(可选)
其实大部分深度学习玩家都无需在宿主机上直接安装cuda,cuda一般是装在容器或者虚拟环境内。
但是偶尔会需要用到本机的CUDA,所以本文也提出了安装方式
apt-cache search cuda-toolkit本文选择了安装最新的CUDA12.4
apt install cuda-toolkit-12-4安装完成后需要添加一下环境变量
vim ~/.bashrc在末尾添加以下俩行
export PATH=/usr/local/cuda-12.4/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-12.4/lib64:$LD_LIBRARY_PATH
#注意cuda版本应该与你安装的一致使其生效
source ~/.bashrc安装完成后可以通过一下命令检测你的CUDA的版本
nvcc -V
安装anaconda
都2024年了,写python一定要用anaconda!
前往https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/?C=M&O=D获取最新的anaconda链接并下载
然后传给你的服务器,因为直接wget会403
安装过程

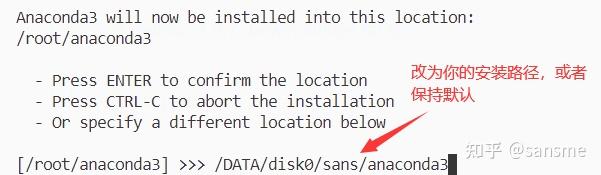

安装完成后,新建终端就来到了base环境了
安装Docker以及NVIDIA容器工具
都2024年了,容器环境的重要性不用我多说!
安装Docker
Docker的安装方式有很多,但是网上的教程前篇一律且让人难受,让我十分痛心,故本文则提出我推荐的安装方式。
社区脚本安装
只要能连上公网,推荐直接通过社区脚本安装
curl -fsSL https://get.docker.com -o get-docker.sh
chmod +x get-docker.sh
./get-docker.sh --mirror Aliyun
# 这里使用了阿里源可通过以下命令验证docker安装
docker安装NVIDIA容器工具
这个工具已经被称为nvidia-docker2,现已被并入官方工具包改名为nvidia-container-toolkit,国内网上的教程只会教你装过时的nvidia-docker2,令人痛心。
apt-get install -y nvidia-container-toolkit设置容器运行时
nvidia-ctk runtime configure --runtime=docker
重启docker使其生效
systemctl restart docker那么赶紧启动个容器试试我们的显卡能否在容器环境可用吧
docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi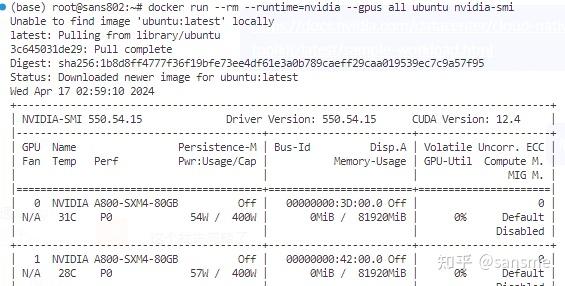
如图所示,我们在容器内找到了我们的显卡
安装NCCL
NCCL已经支持软件源安装,我们直接操作即可
apt install libnccl2 libnccl-dev查看是否安装成功
ldconfig -p | grep libnccl
如图所示出现俩个lib文件,证明你的GPU服务器可以本机进行nccl了
至此我们单台GPU要做的操作其实已经算完成了,OMDD,接下来是让GPU服务器加入集群或者实现多机的操作。
安装OPENMPI
Open MPI 项目是一个由学术界、研究机构和工业伙伴组成的联盟开发和维护的 MPI 规范的开源实现。因此,Open MPI 能够结合高性能计算社区的广泛专业知识、技术和资源,以构建最佳的 MPI 库。Open MPI 对系统和软件供应商、应用开发者以及计算机科学研究者具有优势。
低版本的OPENMPI对于低版本ubuntu的内核或者显卡驱动或者网卡驱动之类的支持不佳,所以最好记得更新你的OPENMPI。
前往https://www.open-mpi.org/software/ompi/ 获取最新的版本
笔者此时最新版本可用此方式下载
wget https://download.open-mpi.org/release/open-mpi/v5.0/openmpi-5.0.3.tar.gz
# 非常的慢,qaq,所以我直接本地下载后scp上去了
tar -xzvf ./openmpi-5.0.3.tar.gz
# 解压
mkdir ./openmpi-5.0.3/build
cd ./openmpi-5.0.3/build
../configure --prefix=/usr/local
make -j all
make install验证OPENMPI
ldconfig
mpirun --version
安装IB&OFED网卡驱动
前往Linux InfiniBand Drivers (nvidia.com)
选择适合你的驱动
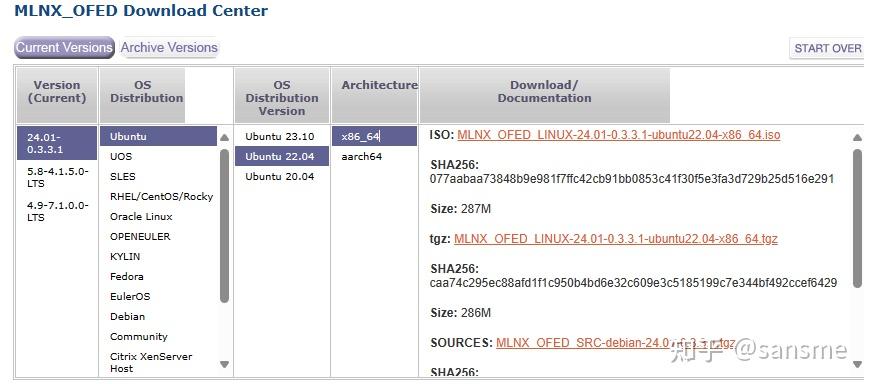
tar -xzvf ./MLNX_OFED_LINUX-24.01-0.3.3.1-ubuntu22.04-x86_64.tgz
# 解压
cd MLNX_OFED_LINUX-24.01-0.3.3.1-ubuntu22.04-x86_64
apt install dracut-core
dracut --force
# 先更新initramfs
./mlnxofedinstall --without-fw-update --all --force
# --without-fw-update 静默安装 --force 无人值守安装 --add-kernel-support 以免内核太新无法支持,某些系统需要添加这个参数
# 如果系统缺一些包会自动装上,装不上的可以看Log手动装上
/etc/init.d/openibd restart
# 重启网卡,可能会导致以太网网卡挂掉,重启即可
service openibd start验证IB网卡是否正常
systemctl status openibd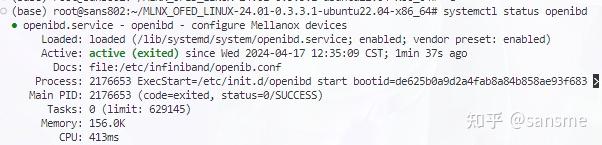
查看IB网卡
ibdev2netdev
可以看到都是down的状态,让我们把它们一个个打开
ifconfig ib网卡名 up
安装OPENSM
在GPU所在集群中至少需要一个opensm server,我所在的GPU集群已经有一个了,故不再赘述。
apt install opensm验证
systemctl status opensm.service检查IB网卡状态
ibstat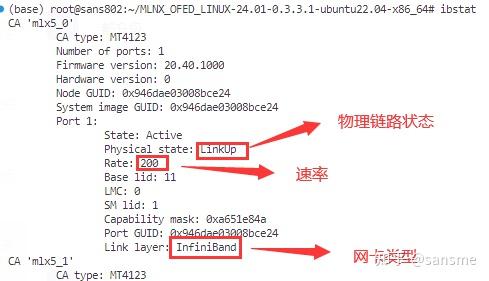
安装NCCL-SHARP
前往Mellanox/nccl-rdma-sharp-plugins: RDMA and SHARP plugins for nccl library (github.com)进行下载
unzip ./nccl-rdma-sharp-plugins-master.zip -d ./
cd ./nccl-rdma-sharp-plugins-master
./autogen.sh
./configure --with-cuda=/usr/local/cuda
#CUDA 安装默认目录,记得安装
make
make install
#生成的库文件放在/usr/local/lib 下,与NCCL的安装路径一致安装完成后可以在OPENSM server上配置SHARP server 功能,本文不再赘述
安装NCCL-TEST
git clone https://github.com/NVIDIA/nccl-tests.git
cd nccl-tests
make MPI=1 MPI_HOME=/usr/local/bin
#如果按照本教程安装的mpi,位置就在/usr/local/bin
#如果CUDA和NCCL没有安装在默认位置需要指定这两项 CUDA_HOME=/path/to/cuda NCCL_HOME=/path/to/nccl加载nvidia_peermem
modprobe nvidia_peermem验证
lsmod |grep -i nvidia_peermem
ldconfig -p | grep libnccl
# 验证nccl能否跑多机,比之前多出俩个,说明成功了
验证
IB网卡传输单机验证
ib_read_bw -a -d mlx5_0 另开终端
ib_read_bw -a -F 127.0.0.1 -d mlx5_1 --report_gbiNCCL-TEST单机验证
/root/nccl-tests/build/all_reduce_perf -b 8 -e 8192M -f 2 -g 8
# 注意一下nccl-tests路径IB网卡传输多机验证
ib_read_bw -a -d mlx5_0
ib_read_bw -a -F X.X.X.X -d mlx5_1 --report_gbi
# 对端内网ip地址



